An 11-tool MCP research surface over SWORD and the Church Fathers — built in 59 days.
Pastoral Research MCP wraps the SWORD Bible library (CrossWire C++ binaries) and 102 CCEL patristic texts behind the Model Context Protocol — exposing scripture, commentary, cross-references, and early-church writings as first-class LLM tools. One engineer, 59 days, 38 PRs, three tagged releases, zero reverts.
LLMs asked theological or biblical questions either hallucinate or call generic web search. The authoritative corpus — SWORD modules and patristic texts — only ships as CLI binaries and ThML XML, with no typed interface a model can call. Building that interface means wrapping a C++ toolchain, ingesting 102 ThML files, and indexing over a million cross-reference citations behind a tool surface an LLM can plan against.
A production MCP server exposing 11 typed tools — backed by Postgres, Redis (with HNSW vector indexes), Neo4j, and an ONNX semantic-search layer. 1,049,029 citations indexed. 2,019 tests at 97%+ coverage. First production release on day 21; full knowledge-graph stack shipped in a single six-day sprint to v2.0.
What we built, and how fast
Pastoral Research MCP is a Model Context Protocol server that turns the SWORD Bible library and 102 CCEL ThML patristic texts into 11 first-class tools an LLM can call. Scripture passages, commentary excerpts, dictionary entries, cross-references, patristic references, general-book navigation, and semantic search — each one a typed contract, not a raw text dump. Behind the tool surface: Postgres for canonical entities, Redis Stack for cache and HNSW vector indexes, Neo4j for the knowledge graph, and ONNX (Xenova/all-MiniLM-L6-v2) for embeddings.
The build itself is the story. From first commit on 2026-01-22 to the latest activity on 2026-03-22 was 59 days. It took 246 commits and 38 pull requests — every one merged through review, zero reverts — produced by a single engineer running an agent-orchestrated workflow. The peak six-day sprint (Feb 24 → Mar 02) shipped Redis caching, ONNX embeddings, a RediSearch vector store, semantic search, and a Neo4j knowledge graph in ten merged PRs. Same-day merge rate held at 79% across the whole build.
Who it's for, and what was at stake
The audience is the LLM application layer — anyone building an agent or assistant that needs to ground a theological or biblical answer in primary sources rather than training-data vibes. MCP makes that audience addressable: an Anthropic or OpenAI client points at the server, discovers the tool surface, and plans queries the same way it would call any other tool. The constraint is on the server side: turning a C++ binary toolchain and a folder of ThML XML into a contract a model can actually use.
Three things made the build sharper than the goal. SWORD ships as diatheke, mod2imp, and vs2osisref CLI binaries — wrapping them required process isolation, output parsing, and a strict no-host-execution policy. The CCEL dataset (102 ThML XML files, 6 SWORD commentary modules) wouldn't parse incrementally — full ingestion was the only useful state. And the MCP spec was new; the reference SDK was newer; production-grade tool surfaces had to be invented as the build went.
Two tools, neither finishing the job
Raw text retrieval over scripture dumps
The default move is to embed a Bible translation and a commentary corpus into a vector store and let the LLM do RAG over chunks. It works for verse lookup. It collapses on cross-references, range parsing, versification mapping between translations, and the structured relationships between a Church Father quoting a verse and the verse itself. The model gets text; it doesn't get a queryable corpus.
Direct SWORD CLI invocation from the agent
Some teams shell out to diatheke from agent code. That puts a C++ toolchain on every host, ties the agent to bash semantics, and gives the model no schema to plan against — it has to know the CLI flags, parse the output, and re-implement reference normalization per integration.
Hand-built REST wrappers, per project
Each LLM app rebuilds its own thin HTTP layer over scripture and commentary, with its own ad-hoc JSON shapes and its own re-ingestion of the patristic corpus. The work is duplicated; the contracts diverge; nothing is reusable across clients.
Agent-orchestrated execution against a phased PR plan
The repository was built under an agent-driven workflow — specialist subagents carried sub-phases under a primary plan, with the pattern visible in commit messages and PR descriptions naming Skill: and Agent: fields per task.
All code written under a strict red/green/refactor TDD cycle — a failing test first, minimal code to pass, then refactor. Test counts tracked PR-by-PR in commit messages and CLAUDE.md updates. The receipt: 2,019 unit tests at 97%+ coverage, growing roughly 34 tests/day across 59 days.
Phase planning and interface design preceded every PR-sized increment. The CLAUDE.md phase ledger reads almost identically to the git tag-and-PR history — Phase 0 through Phase 7.6, then v2.2 Phases B/C/D — because planning happened at the level the work would actually merge in.
Owned every branch, merge, PR, and release. The receipt: 38 of 38 PRs merged through review, zero reverts, 79% same-day merge rate, three clean release tags (v1.1, v1.5, v2.0).
Docker, NestJS, TypeORM, Neo4j/Cypher, and Redis work each invoked a dedicated skill — framework conventions stayed consistent without the human re-deciding them per task.
A typed tool surface, not a text dump
Eleven MCP tools live, all wired through one <code style="font-family:var(--font-mono);color:var(--accent-400)">KnowledgeService</code>, backed by Postgres + Redis + Neo4j with graceful degradation. Here is what the v2.0 surface looks like.
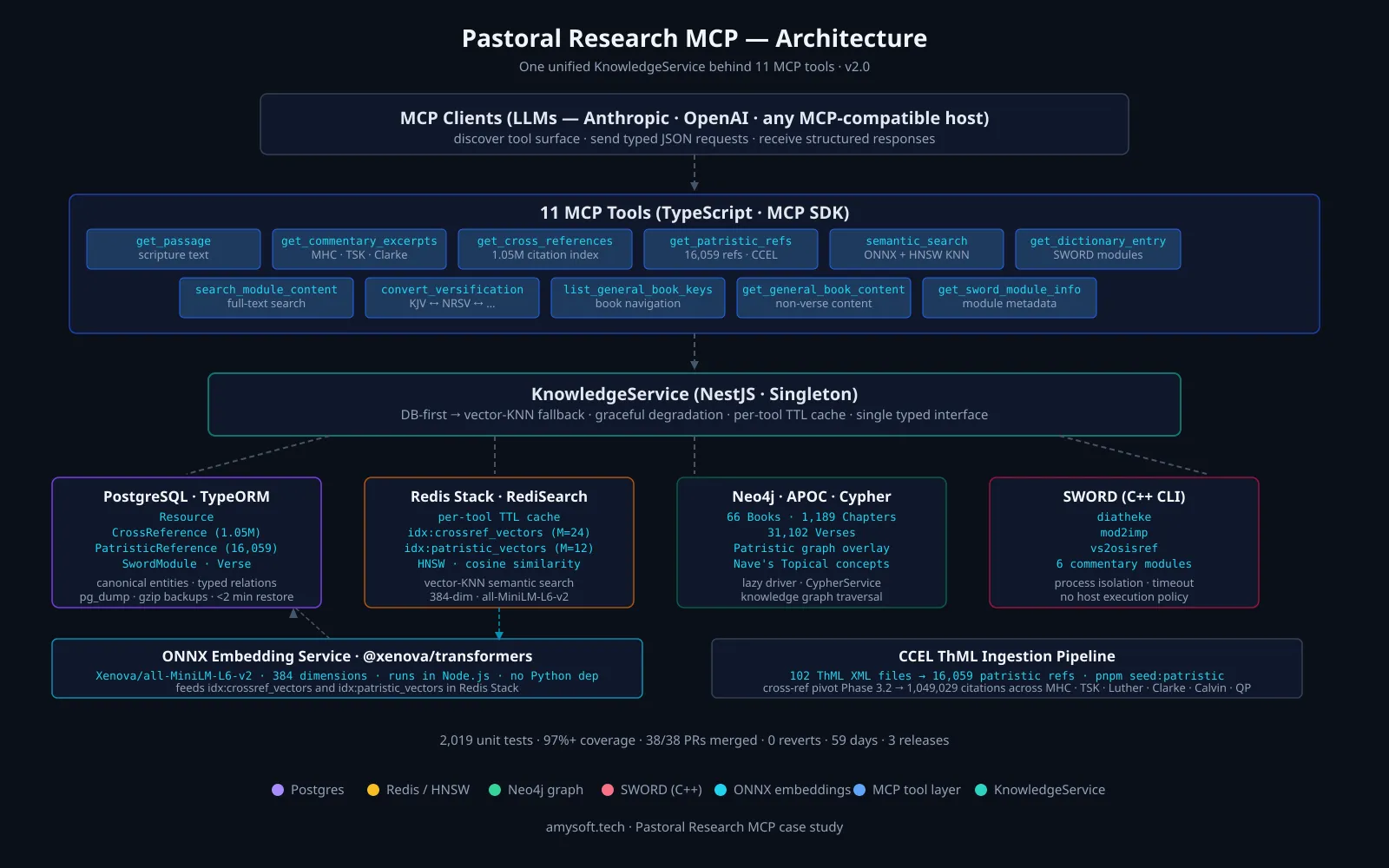
One unified data layer behind 11 tools. SWORD CLI binaries (diatheke / mod2imp / vs2osisref) sit at the floor; five NestJS SWORD services wrap them with timeout discipline and output parsing. Postgres holds canonical entities (Resource, CrossReference, PatristicReference, SwordModule); Redis Stack runs the cache and two HNSW vector indexes; Neo4j carries the knowledge graph. A single KnowledgeService unifies access — DB-first or vector-KNN with graceful fallback — and the 11 MCP tools become thin validators on top of one well-shaped interface.
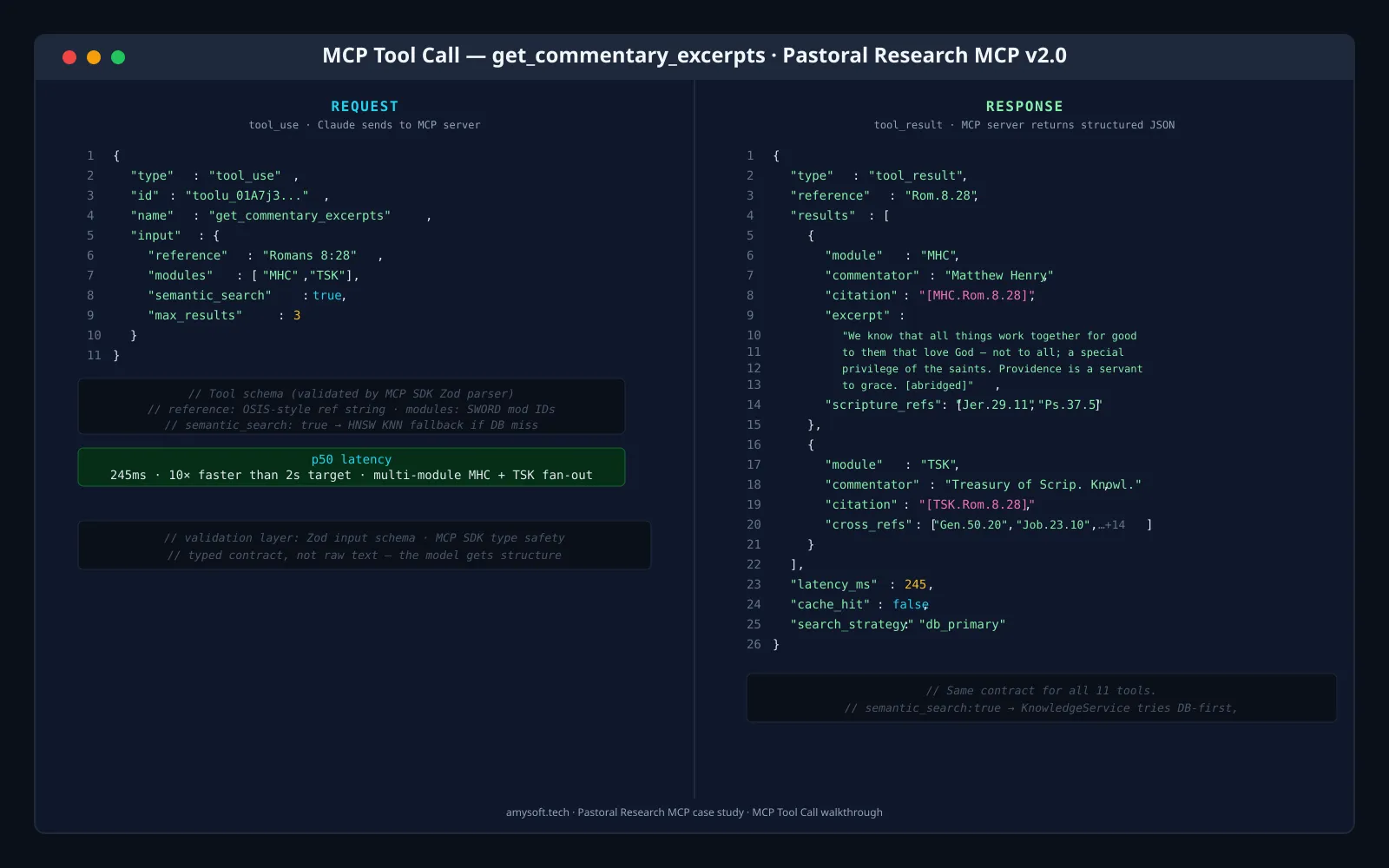
Typed JSON, not raw text retrieval. An LLM calls get_commentary_excerpts with a passage reference and gets back a structured response — module identifier, commentator, excerpt text, embedded scripture references already extracted. Multi-module queries across MHC + TSK in 245ms p50, 10× better than the 2s target. Same contract whether the model wants raw passage text, dictionary entries, cross-references, or patristic citations.
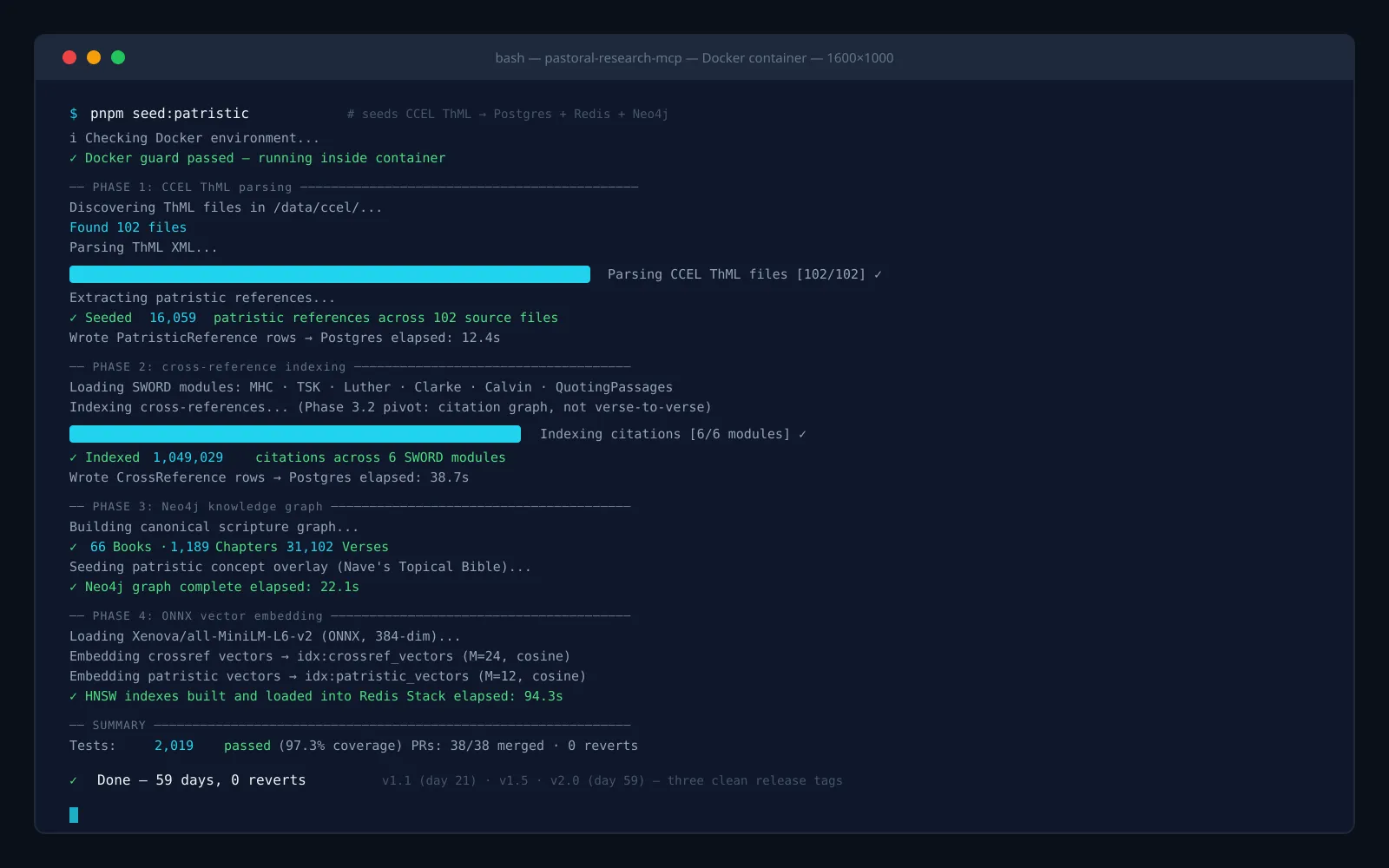
The ingestion that backs the tools. CCEL ThML parsing produces 16,059 patristic references seeded across 102 source files. The cross-reference index — pivoted in Phase 3.2 away from naive verse-to-verse relationships — ends at 1,049,029 citations across six SWORD modules (MHC, TSK, Luther, Clarke, CalvinCommentaries, QuotingPassages). The Neo4j graph carries 66 books, 1,189 chapters, and 31,102 verses, with patristic and concept (Nave's Topical Bible) graphs layered on top.
Three acts, then a deliberate consolidation
Commit clustering reveals three release acts and one post-v2.0 consolidation phase — the unevenness is itself part of the story.
Foundation & first release
Three weeks of scaffolding and data. PR #1 stood up Docker + the MCP SDK; PR #3 wrapped SWORD as five NestJS services with timeout discipline; PR #4 landed the TypeORM schema (57 files, 11,269 additions). PRs #5–#9 shipped five MCP tools in a single day. PR #13 closed the act — the full CCEL ingestion pipeline (12,017 lines added), 16,059 patristic references seeded, and the cross-reference index ending at <strong>1,049,029 citations</strong> across six SWORD modules. Tagged v1.1 on day 21.
Tooling maturity
The focus shifted from "does it work?" to "can we run it in anger?" PRs #14–#16 delivered compressed <code style="font-family:var(--font-mono);color:var(--accent-400)">pg_dump</code> backups with gzip integrity verification, manifest tracking, file-based concurrency locks, fail-safe seeding, and Makefile targets — disaster recovery under two minutes. PR #17 added five more SWORD tools (<code style="font-family:var(--font-mono);color:var(--accent-400)">list_general_book_keys</code>, <code style="font-family:var(--font-mono);color:var(--accent-400)">get_general_book_content</code>, <code style="font-family:var(--font-mono);color:var(--accent-400)">get_dictionary_entry</code>, <code style="font-family:var(--font-mono);color:var(--accent-400)">search_module_content</code>, <code style="font-family:var(--font-mono);color:var(--accent-400)">convert_versification</code>), bringing the total to 11.
The knowledge layer
The run that proves the build. <strong>Six days. Ten PRs. Five new infrastructure layers.</strong> Redis cache wired into every tool with per-tool TTLs (PR #18); ONNX <code style="font-family:var(--font-mono);color:var(--accent-400)">Xenova/all-MiniLM-L6-v2</code> embedding service (PR #19); RediSearch HNSW indexes <code style="font-family:var(--font-mono);color:var(--accent-400)">idx:crossref_vectors</code> (M=24) and <code style="font-family:var(--font-mono);color:var(--accent-400)">idx:patristic_vectors</code> (M=12) (PR #20); semantic search via <code style="font-family:var(--font-mono);color:var(--accent-400)">KnowledgeService</code> with DB-first / vector-KNN fallback (PR #21); Neo4j knowledge graph with lazy driver + Cypher service + APOC (PR #22). Tagged v1.5 + v2.0 on Mar 02.
Consolidation
Net-new feature work slowed; correctness, validation, and tunability moved to the front. PR #28 was a same-day fix for a Node startup crash after <code style="font-family:var(--font-mono);color:var(--accent-400)">@xenova/transformers</code> v2→v3 broke DI ordering. PRs #29–#32 patched vector metadata gaps, Neo4j orphan refs, semantic-path graph enrichment, and cache invalidation. PR #33 added validation infra — cache logging, latency benchmarks, theological-quality eval. PRs #34–#36 (Phase B) made embedding dimension env-configurable, added contextual metadata prefixes, and introduced a <code style="font-family:var(--font-mono);color:var(--accent-400)">TextChunkerService</code>. PR #37 named the honest cost: full Redis + Neo4j reseed required. PR #38 surfaced <code style="font-family:var(--font-mono);color:var(--accent-400)">ResearchController</code> — the project starts looking outward.
Discipline at speed, not just speed
Every figure below is drawn from git and gh history, read-only, anchored on the 246 commits across all refs in the 59-day window.
Commits per active day — 30 of 53 calendar days
Commit-type distribution · 346 commits
Quality signals
CLAUDE.md reads almost identically to the git tag-and-PR history Where the workflow needed a human
A case study that only lists wins isn't evidence. The same git history that proves the pace also marks exactly where judgment had to stay with the human.
PR #37 named the honest cost: a full reseed
Full chunk text storage triggered OOM during vector seeding. The architectural fix — revising the chunk-text contract, lifting minLength 50→120, restoring missing RETURN fields — was the right call. The honest cost was named in the PR title: a full Redis + Neo4j re-seed required before next use. The build is paused on a known good state pending that re-seed.
@xenova/transformers v2 → v3 break
A dependency upgrade silently changed initialization order and broke DI wiring for EmbeddingService. The server wouldn't boot. PR #28 fixed it same-day — but it shipped one day after the v2.0 release tag, which means v2.0 went out with a known startup risk that only surfaced in fresh-container boots.
Six bugs in five days, all post-v2.0
PRs #28–#32 and #37 all surfaced once the system was being exercised against full datasets in the v2.2 validation phase. Unit tests passed throughout — the fixes are evidence that validation infrastructure (PR #33) was earning its keep, but they're also evidence that 1,980+ unit tests at 97% coverage did not catch six real defects. Synthetic data only takes the test suite so far.
Bus factor of one
246 commits across two git identities — one engineer. The agent-orchestrated workflow multiplies that one person's output; it does not reduce the risk that they hold the whole picture alone. No second reviewer, no second runtime, no second person who has booted the full Postgres + Redis + Neo4j + ONNX stack against the real dataset.
What this build teaches the next one
Validation infrastructure pays for itself inside one phase
PR #33's cache logging, latency benchmarks, and theological-quality eval landed on Mar 14. Five of the six v2.2 bugs were named, scoped, and patched inside the next 48 hours — three of them inside 24. Without the validation surface, those bugs would have shipped to whatever called the server next. Build the diagnostics before you need them, not after.
Zero reverts is a discipline, not luck
Every bug was fixed forward. The closest thing to a rollback was PR #37's reseed mandate — shipped as additive correctness, not a code revert. The discipline costs more thinking on the way in (which PR to ship, which to bundle) and pays back as a git history that's a coherent narrative instead of a series of "oops, undo".
Docker-only kills an entire class of bug
Guard scripts in package.json and scripts/check-docker.js block host execution from day one. Result across 59 days: zero "works on my machine" incidents, zero SWORD-binary-missing surprises in tests, zero environment drift. For a build with a C++ toolchain at the bottom, this is the difference between shipping and not shipping.
Same-day merge is a discipline signal, not just a speed metric
79% of PRs merged the day they opened. That isn't an artifact of a solo developer skipping review — it's the signal that scope was right-sized, CI was honest, and make test was the bottleneck, not human latency. If same-day merge rate starts dropping, the PR sizes have drifted up.
One <code>KnowledgeService</code> beats five tool-specific data layers
MCP tools became thin validators on top of one well-shaped interface. When semantic search and graph enrichment landed in PRs #21–#22, they slotted into the existing KnowledgeService as new code paths with graceful fallback — not as a parallel data layer. PR #25's EmbeddingService extraction was 50 additions and 21 deletions across 15 files because the boundary was already in the right place.
Need an MCP server that ships in weeks, not quarters?
Typed tool surfaces, real datastores, honest test coverage. Fixed price, fixed timeline, source-code handoff. We'll tell you on a free 30-minute call whether we're the right fit.