A production AI platform, shipped in 53 days — with the git history to prove it.
ElderAgent is a streaming AI platform for biblical scholarship where every answer is grounded in verifiable sources. We took it from an empty repository to four production releases in under six weeks — single developer, agent-driven workflow, zero reverts.
Generic AI invents plausible-sounding doctrine with no traceable sources. Traditional Bible software has the sources but no conversation. Faithful study needs both — answered in seconds, every claim citable.
A consumer SaaS that streams citation-rich answers from a real research pipeline — first production release on day 35, four tagged releases in a 37-day span, every change merged through review.
What we built, and how fast
ElderAgent answers theological questions in plain language and backs every claim with a clickable citation — drawing from 916,930 cross-references, the Treasury of Scripture Knowledge, Matthew Henry's Commentary, the Church Fathers, and the SWORD biblical text library, assembled in real time and handed to Anthropic Claude as grounding context.
The build itself is the story. From first commit on 19 March to the v1.2.0 release on 27 April was 39 days; the first production release landed on day 35. It took 346 commits and 126 pull requests — every one merged through review — produced by a single developer running an explicitly agent-driven workflow. The git history is the audit trail, and it shows both what the workflow is good at and where a human still has to hold the line.
Who it's for, and what was at stake
The users are pastors, seminarians, lay leaders, and the spiritually curious — people for whom unsourced answers are a non-starter. They already had two unsatisfying options, and neither did the whole job.
The build had to prove a thesis at the same time: that an AI-native studio workflow could carry a non-trivial product — three datastores, a C++ toolchain integration, billing, real-time streaming — to production fast enough to matter, without trading away the engineering discipline that makes it safe to ship.
Two tools, neither finishing the job
Generic AI chatbots
ChatGPT, Gemini, and Claude.ai will answer any theological question — but they generate doctrine from training data with no traceable sources. For faithful study, that's vibes, not scholarship.
Traditional Bible software
Logos, Accordance, and BibleHub have the sources but no conversation. Users must know exactly what they're looking for, navigate dense interfaces, and assemble the answer themselves.
Agents executed the process; the human held the judgment
The repository was built under an agent-driven workflow mandated in the project's CLAUDE.md — a specialist implementation agent, a git-flow agent, and per-task domain skills.
All code written under a strict red/green/refactor TDD cycle — a failing test first, minimal code to pass, then refactor. Consistent conventions across 441 TypeScript files.
Owned every branch, merge, PR, and release. The receipt: 125 of 125 merged PRs went through review, zero direct feature commits to develop, zero commits to master.
Docker, Angular, NestJS, and Nx work each invoked a dedicated skill — framework conventions stayed consistent without the human re-deciding them each time.
The product those commits produced
Not a prototype — a working consumer SaaS. Here is what day 35 actually looked like.
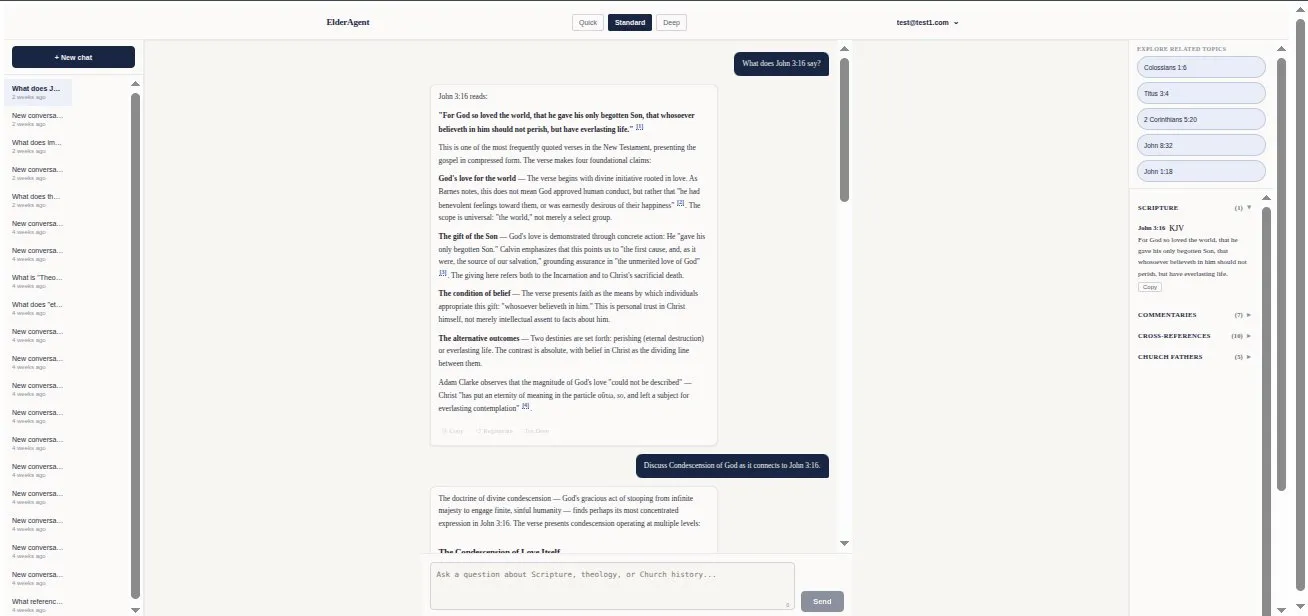
Streaming, citation-rich answers. Inline [n] markers, a live Scripture / Commentaries / Cross-references / Church Fathers panel, and follow-up topic chips — the conversational ease of a chatbot with the source integrity of a research library.
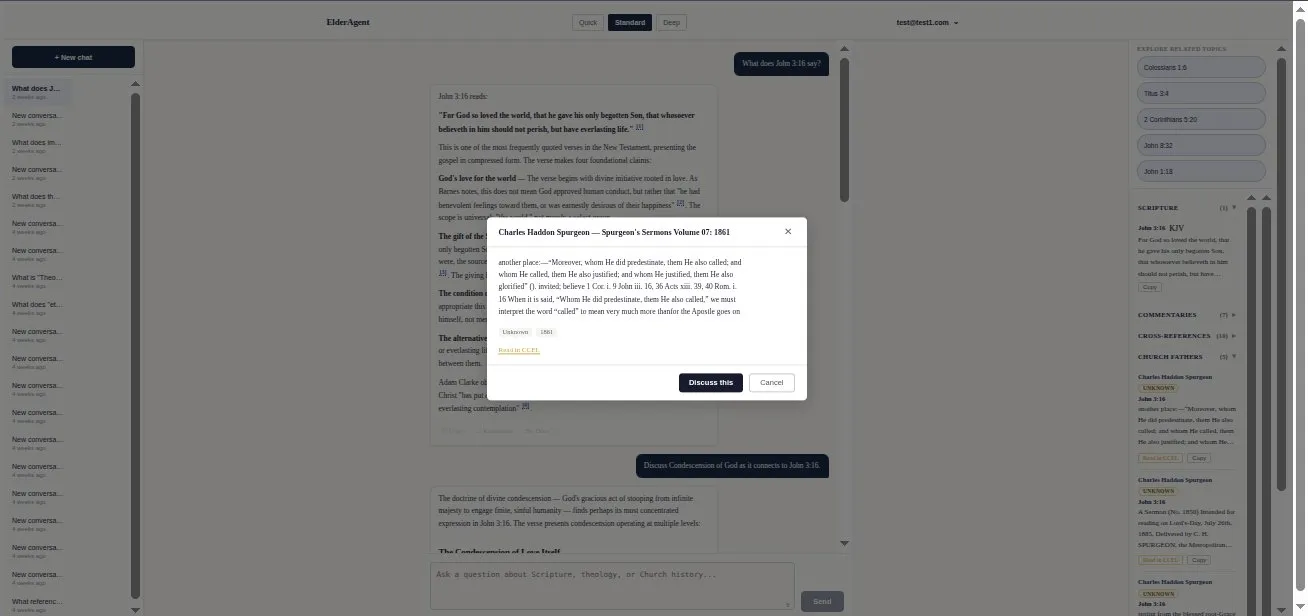
Every claim is verifiable. A citation opens to its exact source — here a Spurgeon sermon via CCEL — so the user checks the scholarship rather than trusting the model. This is the entire product thesis, on screen.
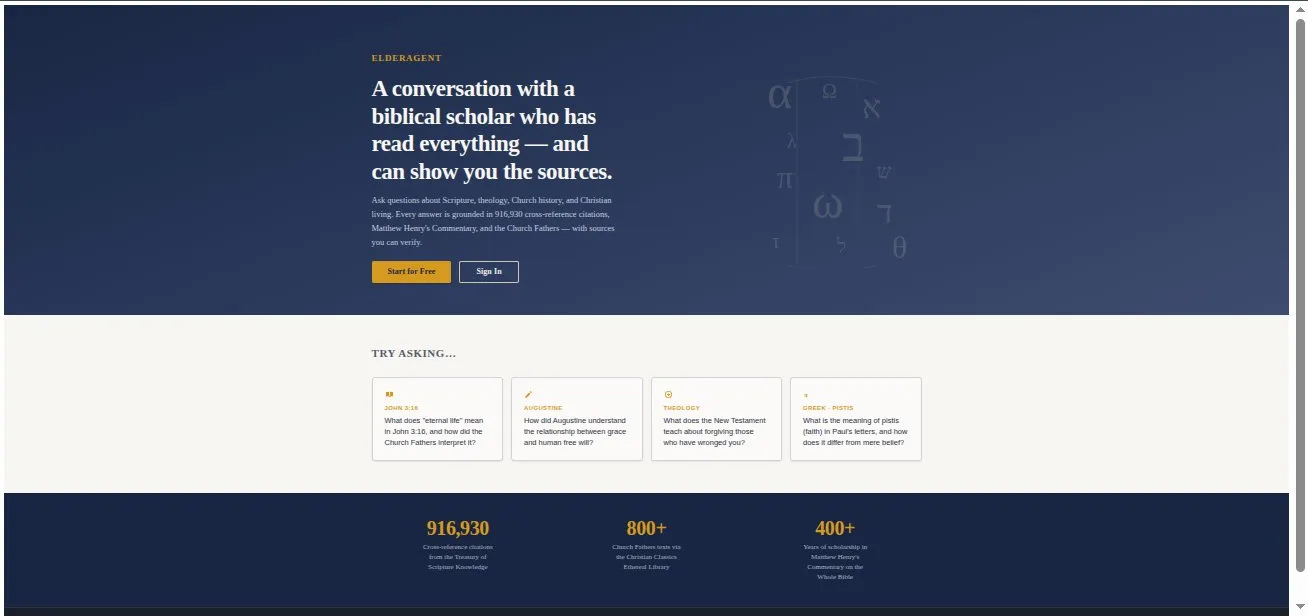
Plain-language entry. Curated example prompts lower the blank-page barrier; the corpus is stated up front — 916,930 cross-references, 800+ Church Fathers texts, 400+ years of commentary.
Five phases, wildly uneven velocity
Commit clustering reveals five distinct phases — and the unevenness is itself part of the story.
Infrastructure & SWORD
Two enormous scaffolding commits stood up the Nx monorepo and Docker services, then the hardest integration in the project: the SWORD C++ Bible toolchain, compiled from source. The integration fought back — a +5,561/−1,237 fix landed before real scripture data would read.
Specification & foundation
The slowest stretch, deliberately so. Seven active days produced the formal spec set — BRD, SRS, HLD, LLD, WBS, RTM, Design Spec. Engineering throughput was near zero, but the spec written here is what made the next phase possible.
The execution sprint
The build's engine. In seven days: SSE-streaming chat, conversation sidebar, auth, Postgres row-level security, tier limiting and quota, the citation panel, the landing page. Daily counts ran 23–40. Closed with the first production release on day 35.
Release cadence
Three releases in five days. v1.1.0 delivered chat depth and data quality; v1.1.1 followed it by 58 minutes as a hotfix; v1.2.0 added modal cross-references and a free-tier model path. Fast, disciplined — and, as the hotfix shows, running ahead of its own QA.
Polish & audit prep
Velocity dropped hard — 11 commits across 13 days against 278 in the prior 12. Work shifted to the layout trio and audit prerequisites. A deliberate cooldown into a quality phase, but a gradient steep enough to watch.
Consistency at speed, not just speed
Every figure below is drawn from git and gh history, read-only, anchored on the 346 commits reachable from develop.
Commits per active day — 30 of 53 calendar days
Commit-type distribution · 346 commits
Quality signals
Where the workflow needed a human
A case study that only lists wins isn't evidence. The same git history that proves the pace also marks exactly where judgment had to stay with the human.
A fix-heavy profile · 1.53 fixes per feature
118 fixes to 77 features. Some is healthy tight-loop iteration — but a ratio this high also says features reached develop before they were fully validated, and the cost was paid in follow-up fixes.
v1.1.0 outran its QA
v1.1.1 shipped 58 minutes after v1.1.0 to patch a data-backfill bug. The hotfix was handled well — but it shouldn't have been needed. The release was tagged before it was smoke-tested.
Bus factor of one
Two git identities, one email — effectively a one-person build. The agent-driven workflow multiplies that person's output; it doesn't reduce the risk that they hold the whole picture alone.
Open architectural debt
The API has no production build — esbuild can't handle NestJS decorator metadata, so production runs the dev strategy. Acceptable for v1; documented in an ADR; to be retired before real load.
What this build teaches the next one
Add a release gate between "tagged" and "shipped."
A mandatory smoke-test pass should precede tagging, not follow it. A short scripted post-build smoke would have caught the bug before v1.1.0 went out.
Track the fix:feat ratio as a release-health metric.
1.53:1 is the baseline this build set. A rising ratio means features are shipping under-validated; a falling one means the test-first loop is catching more before merge.
Reduce the bus factor.
Agent-driven development makes one person far more productive; it doesn't make the project survivable without them. Add a second reviewer; keep investing in the written spec.
Make the post-release cooldown deliberate.
The velocity cliff is fine if it's a planned audit phase with exit criteria — so "cooldown" doesn't quietly become "stall."
Have a product that needs to ship in weeks, not quarters?
Fixed price, fixed timeline, source-code handoff. We'll tell you on a free 30-minute call whether we're the right fit.